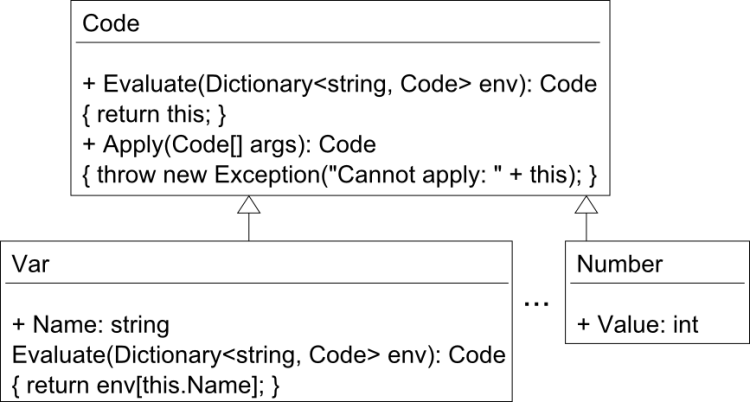
Listing 5: Evaluator – algebraische Datentypen / Pattern matching
/// Stellt einen Ausdruck oder ein Ergebnis einer simplen Programmiersprache dar.
type Code =
/// Number(Konstante Ganzzahl)
| Number of int
/// Bool(Konstanter Wahrheitswert)
| Bool of bool
/// Var(Name)
| Var of string
/// Binding(Name, Wert, Ausdruck)
| Binding of string * Code * Code
/// Conditional(Bedingung, Folge, Alternative)
| Conditional of Code * Code * Code
/// Application(Funktion, Argument-Liste)
| Application of Code * Code list
/// Lambda(Parameter-Namen, Ausdruck)
| Lambda of string list * Code
/// Closure = Lambda + Variablenbindungen
| Closure of Map<string, Code> * string list * Code
/// BuiltInFunc(F#-Funktion) (die Funktion erhält ausgewertete Argumente)
| BuiltInFunc of (Code list -> Code)
module Evaluator =
let rec eval env expr =
match expr with
| Number _ | Bool _ | BuiltInFunc _ | Closure _ -> expr
| Lambda(param, body) -> Closure(env, param, body)
| Var name -> Map.find name env
| Binding(name, value, body) ->
eval (Map.add name (eval env value) env) body
| Conditional(condition, thenExpr, elseExpr) ->
match eval env condition with
| Bool false -> eval env elseExpr
| _ -> eval env thenExpr
| Application(func, args) ->
match eval env func with
| Closure(extendedEnv, names, body) ->
let addToMap map (key, value) = Map.add key value map
let newEnv = List.fold addToMap extendedEnv (List.zip names (List.map (eval env) args))
eval newEnv body
| BuiltInFunc(func) ->
func (List.map (eval env) args)
| other -> failwithf "Only closures and built-in functions can be applied, found: %A" other
let Evaluate(expr) = eval Map.empty expr
module BuiltInFuncs =
let toNumber = function
| Number value -> value
| other -> failwithf "Integer expected, found: %A" other
let equality = function
| Number value1, Number value2 -> value1 = value2
| Bool value1, Bool value2 -> value1 = value2
| _ -> false
let plus() = BuiltInFunc(fun args ->
Number(List.sumBy toNumber args))
// let (|>) x f = f(x) // Pipelining [FSharp, vgl. S. 40-41]
let times() = BuiltInFunc(fun args ->
args |> List.map toNumber |> List.fold (*) 1 |> Number)
// geschachtelte Schreibweise ohne (|>)
let times'() = BuiltInFunc(fun args ->
Number(List.fold (*) 1 (List.map toNumber args)))
let eq() = BuiltInFunc(fun args ->
args |> Seq.pairwise |> Seq.forall equality |> Bool)
let lt() = BuiltInFunc(fun args ->
args |> Seq.map toNumber |> Seq.pairwise
|> Seq.forall(fun(a, b) -> a < b) |> Bool)
open Evaluator
open BuiltInFuncs
#if INTERACTIVE
#I "C:\Program Files (x86)\Microsoft Visual Studio 11.0\Common7\IDE\PublicAssemblies"
#r "Microsoft.VisualStudio.QualityTools.UnitTestFramework.dll"
#endif
open Microsoft.VisualStudio.TestTools.UnitTesting
open System
open System.Reflection
[<TestClass>]
type FunctionalTests() =
let (-->) expr result =
let raw = function
| Number x -> box x
| Bool b -> box b
| _ -> obj()
let evaluated = Evaluate(expr)
Assert.AreEqual(raw evaluated, raw result,
sprintf "expected %A <> actual %A (expr: %A)"
result evaluated expr)
static member RunInConsole() =
let tester = FunctionalTests()
let tests =
typeof<FunctionalTests>.GetMethods()
|> Array.filter(fun test ->
Attribute.IsDefined(test, typeof<TestMethodAttribute>))
let mutable passed = 0
for test in tests do
try
test.Invoke(tester, null) |> ignore
passed<- passed + 1
printfn "OK: %s" test.Name
with :? TargetInvocationException as e ->
try raise(e.InnerException)
with :? AssertFailedException as e ->
printfn "%s\n%s\n"
test.Name (e.Message.Replace(". ", "\n"))
printfn "\n%d von %d Tests bestanden." passed tests.Length
[<TestMethod>]
member this.FunctionalLet() =
let sample = // (let ([x 20]) (+ x x 4))
Binding("x", Number 20,
Application(plus(), [Var "x"; Var "x"; Number 4]))
sample --> Number 44
[<TestMethod>]
member this.FunctionalSquare() =
let square = // (lambda (x) (* x x))
Lambda(["x"], Application(times(), [Var "x"; Var "x"]))
for i = -100 to 100 do
Application(square, [Number i]) --> Number(i * i)
[<TestMethod>]
member this.FunctionalMinimum() =
let minimum = // (lambda (a b) (if (< a b) a b))
Lambda(["a"; "b"],
Conditional(Application(lt(), [Var "a"; Var "b"]),
Var "a", Var "b"))
for i = -10 to 10 do
for k = -10 to 10 do
Application(minimum, [Number i; Number k]) --> Number(min i k)
[<TestMethod>]
member this.FunctionalFactorial() =
// "Rekursiver" Lambda-Ausdruck:
// (lambda (cont x) (if (= x 0) 1 (* x (cont cont (- x 1)))))
let factorial =
Lambda(["cont"; "x"],
Conditional(
Application(eq(), [Var "x"; Number 0]),
Number 1,
Application(times(),
[Var "x"; Application(Var "cont",
[Var "cont"; Application(plus(),
[Var "x"; Number -1])])])))
for i = 0 to 10 do
Application(factorial, [factorial; Number i])
--> Number(Seq.fold (*) 1 { 1..i })
[<TestMethod>]
member this.FunctionalClosure() =
let cons = // (lambda (hd tl) (lambda (takeHead) (if takeHead hd tl)))
Lambda(["hd"; "tl"],
Lambda(["takeHead"],
Conditional(
Var "takeHead",
Var "hd",
Var "tl")))
let empty = Bool false // #f
let head = // (lambda (consCell) (consCell true))
Lambda(["xs"], Application(Var "xs", [Bool true]))
let tail = // (lambda (consCell) (consCell false))
Lambda(["xs"], Application(Var "xs", [Bool false]))
let isEmpty = // (lambda (consCell) (if consCell #f #t))
Lambda(["xs"], Conditional(Var "xs", Bool false, Bool true))
let oneTwo = // (cons 1 (cons 2 empty))
Application(cons, [Number 1;
Application(cons, [Number 2; empty])])
Application(head, [oneTwo]) --> Number 1
Application(head, [Application(tail, [oneTwo])]) --> Number 2
Application(tail, [Application(tail, [oneTwo])]) --> empty
Application(isEmpty, [empty]) --> Bool true
Application(isEmpty, [oneTwo]) --> Bool false
Application(isEmpty, [Application(tail, [oneTwo])])
--> Bool false
Application(isEmpty, [Application(tail, [Application(tail, [oneTwo])])])
--> Bool true
#if INTERACTIVE
FunctionalTests.RunInConsole()
#endif
Listing 6: Evaluator – datenorientiert mit Typtests
using System;
using System.Collections.Generic;
namespace Typtests
{
abstract public class Code { }
public class Number : Code { public int Value; }
public class Bool : Code { public bool Value; }
public class Var : Code { public string Name; }
public class Binding : Code
{ public string Identifier; public Code Value, Body; }
public class Conditional : Code
{ public Code Condition, Then, Else; }
public class Application : Code
{ public Code Function; public Code[] Args; }
public class Lambda : Code
{ public string[] ParameterIdentifiers; public Code Body; }
public class Closure : Lambda
{ public Dictionary<string, Code> Env; }
abstract public class BuiltInFunc : Code
{ public abstract Code Apply(Code[] args); }
public class Plus : BuiltInFunc
{
public override Code Apply(Code[] args)
{
int sum = 0;
foreach (var item in args)
{ sum += ((Number)item).Value; }
return new Number { Value = sum };
}
}
public class Equals : BuiltInFunc
{
public override Code Apply(Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (x is Number && ((Number)x).Value != ((Number)y).Value
|| x is Bool && ((Bool)x).Value != ((Bool)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class LessThan : BuiltInFunc
{
public override Code Apply(Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (((Number)x).Value >= ((Number)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class Evaluator
{
public Code Evaluate(Code expr)
{ return Evaluate(new Dictionary<string, Code>(), expr); }
public Code Evaluate(Dictionary<string, Code> env, Code expr)
{
if (expr is Number || expr is Bool || expr is BuiltInFunc || expr is Closure)
{ return expr; }
var l = expr as Lambda;
if (l != null)
{
return new Closure
{
Env = new Dictionary<string, Code>(env),
Body = l.Body,
ParameterIdentifiers = l.ParameterIdentifiers
};
}
Var v = expr as Var;
if (v != null)
{ return env[v.Name]; }
var binding = expr as Binding;
if (binding != null)
{
Code old = null;
if (env.ContainsKey(binding.Identifier))
{ old = env[binding.Identifier]; }
env[binding.Identifier] = Evaluate(env, binding.Value);
var result = Evaluate(env, binding.Body);
if (old != null) { env[binding.Identifier] = old; }
return result;
}
var conditional = expr as Conditional;
if (conditional != null)
{
var test = Evaluate(env, conditional.Condition) as Bool;
if (test != null && !test.Value)
{ return Evaluate(env, conditional.Else); }
else
{ return Evaluate(env, conditional.Then); }
}
var app = expr as Application;
if (app != null)
{
var func = Evaluate(env, app.Function);
var f = func as Closure;
if (f != null)
{
var envToExtend = f.Env;
var len = f.ParameterIdentifiers.Length;
var oldValues = new Code[len];
for (int i = 0; i < len; i++)
{
var name = f.ParameterIdentifiers[i];
if (envToExtend.ContainsKey(name))
{ oldValues[i] = envToExtend[name]; }
envToExtend[name] = Evaluate(env, app.Args[i]);
// Werte die Argumente mit env aus, den
} // Körper der Closure mit erweitertem env.
var result = Evaluate(envToExtend, f.Body);
for (int i = 0; i < len; i++)
{
var name = f.ParameterIdentifiers[i];
if (oldValues[i] != null)
{ envToExtend[name] = oldValues[i]; }
}
return result;
}
var prim = func as BuiltInFunc;
if (prim != null)
{
var evaluatedArgs = new Code[app.Args.Length];
for (int i = 0; i < evaluatedArgs.Length; i++)
{ evaluatedArgs[i] = Evaluate(env, app.Args[i]); }
return prim.Apply(evaluatedArgs);
}
throw new Exception(
"Only closures and built-in functions can be applied. Given: "
+ expr);
}
throw new Exception("Unknown subclass of Code: " + expr);
}
}
}
Listing 7: Evaluator – datenorientiert mit switch über Type code
using System;
using System.Collections.Generic;
namespace TypeCodes
{
public enum CodeType
{ Number, Bool, Var, Binding,
Conditional, Application, Lambda, Closure, BuiltInFunc }
public abstract class Code
{ public abstract CodeType Type { get; } }
public class Number : Code
{ public int Value;
public override CodeType Type
{ get { return CodeType.Number; } } }
public class Bool : Code
{ public bool Value;
public override CodeType Type
{ get { return CodeType.Bool; } } }
public class Var : Code
{ public string Name;
public override CodeType Type
{ get { return CodeType.Var; } } }
public class Binding : Code
{
public string Identifier; public Code Value, Body;
public override CodeType Type
{ get { return CodeType.Binding; } }
}
public class Conditional : Code
{
public Code Condition, Then, Else;
public override CodeType Type
{ get { return CodeType.Conditional; } }
}
public class Application : Code
{
public Code Function; public Code[] Args;
public override CodeType Type
{ get { return CodeType.Application; } }
}
public class Lambda : Code
{
public string[] ParameterIdentifiers; public Code Body;
public override CodeType Type
{ get { return CodeType.Lambda; } }
}
public class Closure : Lambda
{
public Dictionary<string, Code> Env;
public override CodeType Type
{ get { return CodeType.Closure; } }
}
public class BuiltInFunc : Code
{
public virtual Code Apply(params Code[] args)
{ throw new Exception(); }
public override CodeType Type
{ get { return CodeType.BuiltInFunc; } }
}
public class Plus : BuiltInFunc
{
public override Code Apply(params Code[] args)
{
int sum = 0;
foreach (var item in args)
{ sum += ((Number)item).Value; }
return new Number { Value = sum };
}
}
public class Equals : BuiltInFunc
{
public override Code Apply(params Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (x is Number && ((Number)x).Value != ((Number)y).Value
|| x is Bool && ((Bool)x).Value != ((Bool)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class LessThan : BuiltInFunc
{
public override Code Apply(params Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (x is Number
&& ((Number)x).Value >= ((Number)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class Evaluator
{
public Code Evaluate(Code expr)
{ return Evaluate(new Dictionary<string, Code>(), expr); }
public Code Evaluate(Dictionary<string, Code> env, Code expr)
{
switch (expr.Type)
{
case CodeType.Number:
case CodeType.Bool:
case CodeType.BuiltInFunc:
case CodeType.Closure:
return expr;
case CodeType.Lambda:
var l = (Lambda)expr;
return new Closure
{
Env = new Dictionary<string, Code>(env),
Body = l.Body,
ParameterIdentifiers = l.ParameterIdentifiers
};
case CodeType.Var:
var v = (Var)expr;
return env[v.Name];
case CodeType.Binding:
var bind = (Binding)expr;
Code old = null;
if (env.ContainsKey(bind.Identifier))
{ old = env[bind.Identifier]; }
env[bind.Identifier] = Evaluate(env, bind.Value);
var result = Evaluate(env, bind.Body);
if (old != null) { env[bind.Identifier] = old; }
return result;
case CodeType.Conditional:
var conditional = (Conditional)expr;
var test = Evaluate(env, conditional.Condition) as Bool;
if (test != null && !test.Value)
{ return Evaluate(env, conditional.Else); }
else
{ return Evaluate(env, conditional.Then); }
case CodeType.Application:
var app = (Application)expr;
var func = Evaluate(env, app.Function);
switch (func.Type)
{
case CodeType.Closure:
var c = (Closure)func;
var envToExtend = c.Env;
var len = c.ParameterIdentifiers.Length;
var oldValues = new Code[len];
for (int i = 0; i < len; i++)
{
var name = c.ParameterIdentifiers[i];
if (envToExtend.ContainsKey(name))
{ oldValues[i] = envToExtend[name]; }
envToExtend[name] =
Evaluate(env, app.Args[i]);
// Werte die Argumente mit env aus, den
} // Körper der Closure mit erweitertem env.
var functionResult =
Evaluate(envToExtend, c.Body);
for (int i = 0; i < len; i++)
{
var name = c.ParameterIdentifiers[i];
if (oldValues[i] != null)
{ envToExtend[name] = oldValues[i]; }
}
return functionResult;
case CodeType.BuiltInFunc:
var b = (BuiltInFunc)func;
var length = app.Args.Length;
var evaluatedArgs = new Code[length];
for (int i = 0; i < length; i++)
{ evaluatedArgs[i] =
Evaluate(env, app.Args[i]); }
return b.Apply(evaluatedArgs);
default:
throw new Exception("Cannot be applied " + func);
}
}
throw new Exception("Wrong CodeType: " + expr.Type + " (of object " + expr + ")");
}
}
}
Listing 8: Evaluator – verhaltensorientiert mit Polymorphie
using System;
using System.Collections.Generic;
namespace Polymorphie
{
abstract public class Code
{
public virtual Code Evaluate(Dictionary<string, Code> env)
{ return this; }
public virtual Code Apply(Dictionary<string, Code> env,
Code[] args)
{ throw new Exception("Cannot apply " + this); }
}
public class Number : Code { public int Value; }
public class Bool : Code { public bool Value; }
public class Var : Code
{
public string Name;
public override Code Evaluate(Dictionary<string, Code> env)
{ return env[Name]; }
}
public class Binding : Code
{
public string Identifier;
public Code Value, Body;
public override Code Evaluate(Dictionary<string, Code> env)
{
Code old = null;
if (env.ContainsKey(Identifier)) { old = env[Identifier]; }
env[Identifier] = Value.Evaluate(env);
var result = Body.Evaluate(env);
if (old != null) { env[Identifier] = old; }
return result;
}
}
public class Conditional : Code
{
public Code Condition, Then, Else;
public override Code Evaluate(Dictionary<string, Code> env)
{
var result = Condition.Evaluate(env) as Bool;
if (result != null && !result.Value)
{ return Else.Evaluate(env); }
else
{ return Then.Evaluate(env); }
}
}
public class Application : Code
{
public Code Function;
public Code[] Args;
public override Code Evaluate(Dictionary<string, Code> env)
{
var func = Function.Evaluate(env);
return func.Apply(env, Args);
}
}
public class Lambda : Code
{
public string[] ParameterIdentifiers;
public Code Body;
public override Code Evaluate(Dictionary<string, Code> env)
{
return new Closure
{
Env = new Dictionary<string, Code>(env),
ParameterIdentifiers = ParameterIdentifiers,
Body = Body
};
}
}
public class Closure : Lambda
{
public Dictionary<string, Code> Env;
public override Code Evaluate(Dictionary<string, Code> env)
{ return this; }
public override Code Apply(Dictionary<string, Code> env, Code[] args)
{
var len = ParameterIdentifiers.Length;
var oldValues = new Code[len];
for (int i = 0; i < len; i++)
{
var name = ParameterIdentifiers[i];
if (Env.ContainsKey(name))
{ oldValues[i] = Env[name]; }
Env[name] = args[i].Evaluate(env);
// Werte die Argumente mit env aus, den
} // Körper der Closure mit erweitertem env.
var result = Body.Evaluate(Env);
for (int i = 0; i < len; i++)
{
var name = ParameterIdentifiers[i];
if (oldValues[i] != null) { Env[name] = oldValues[i]; }
}
return result;
}
}
abstract public class BuiltInFunc : Code
{
public override Code Apply(Dictionary<string, Code> env, Code[] args)
{
var len = args.Length;
var evaluatedArgs = new Code[len];
for (int i = 0; i < len; i++)
{ evaluatedArgs[i] = args[i].Evaluate(env); }
return Apply(evaluatedArgs);
}
protected abstract Code Apply(Code[] evaluatedArgs);
}
public class Plus : BuiltInFunc
{
protected override Code Apply(Code[] args)
{
int sum = 0;
foreach (var item in args)
{ sum += ((Number)item).Value; }
return new Number { Value = sum };
}
}
public class Equals : BuiltInFunc
{
protected override Code Apply(Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (x is Number && ((Number)x).Value != ((Number)y).Value
|| x is Bool && ((Bool)x).Value != ((Bool)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class LessThan : BuiltInFunc
{
protected override Code Apply(Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (((Number)x).Value >= ((Number)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class Evaluator
{
public Code Evaluate(Code expr)
{ return expr.Evaluate(new Dictionary<string, Code>()); }
}
}
Listing 9: Evaluator – verhaltensorientiert mit Visitor pattern
using System;
using System.Collections.Generic;
namespace Visitors
{
abstract public class Code
{ public abstract Code Accept(Visitor v);}
public class Number : Code
{
public int Value;
public override Code Accept(Visitor v)
{ return v.Visit(this); } // Visit(Number)
}
public class Bool : Code
{
public bool Value;
public override Code Accept(Visitor v)
{ return v.Visit(this); } // Visit(Bool)
}
public class Var : Code
{
public string Name;
public override Code Accept(Visitor v)
{ return v.Visit(this); } // usw.
}
public class Binding : Code
{
public string Identifier; public Code Value, Body;
public override Code Accept(Visitor v)
{ return v.Visit(this); }
}
public class Conditional : Code
{
public Code Condition, Then, Else;
public override Code Accept(Visitor v)
{ return v.Visit(this); }
}
public class Application : Code
{
public Code Function; public Code[] Args;
public override Code Accept(Visitor v)
{ return v.Visit(this); }
}
public class Lambda : Code
{
public string[] ParameterIdentifiers; public Code Body;
public override Code Accept(Visitor v)
{ return v.Visit(this); }
}
public class Closure : Lambda
{
public Dictionary<string, Code> Env;
public override Code Accept(Visitor v)
{ return v.Visit(this); }
}
abstract public class BuiltInFunc : Code
{
public override Code Accept(Visitor v)
{ return v.Visit(this); }
public abstract Code Apply(Code[] args);
}
public class LessThan : BuiltInFunc
{
public override Code Apply(Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (((Number)x).Value >= ((Number)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
public class Plus : BuiltInFunc
{
public override Code Apply(params Code[] args)
{
int sum = 0;
foreach (var item in args)
{ sum += ((Number)item).Value; }
return new Number { Value = sum };
}
}
public class Equals : BuiltInFunc
{
public override Code Apply(params Code[] args)
{
for (int i = 0; i < args.Length - 1; i++)
{
var x = args[i];
var y = args[i + 1];
if (x is Number && ((Number)x).Value != ((Number)y).Value
|| x is Bool && ((Bool)x).Value != ((Bool)y).Value)
{ return new Bool { Value = false }; }
}
return new Bool { Value = true };
}
}
abstract public class Visitor
{
public virtual Code Visit(Number expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Bool expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Var expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Binding expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Conditional expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Application expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Lambda expr)
{ return VisitDefault(expr); }
public virtual Code Visit(Closure expr)
{ return VisitDefault(expr); }
public virtual Code Visit(BuiltInFunc expr)
{ return VisitDefault(expr); }
protected abstract Code VisitDefault(Code expr);
}
public class EvaluationVisitor : Visitor
{
Dictionary<string, Code> env;
public EvaluationVisitor()
: this(new Dictionary<string, Code>()) { }
public EvaluationVisitor(Dictionary<string, Code> env)
{ this.env = env; }
protected override Code VisitDefault(Code expr)
{ return expr; }
public override Code Visit(Var expr)
{ return env[expr.Name]; }
public override Code Visit(Lambda expr)
{
return new Closure
{
Env = new Dictionary<string, Code>(env),
Body = expr.Body,
ParameterIdentifiers = expr.ParameterIdentifiers
};
}
public override Code Visit(Binding expr)
{
Code old = null;
if (env.ContainsKey(expr.Identifier))
{ old = env[expr.Identifier]; }
env[expr.Identifier] = expr.Value.Accept(this);
var result = expr.Body.Accept(this);
if (old != null) { env[expr.Identifier] = old; }
return result;
}
public override Code Visit(Conditional expr)
{
var result = expr.Condition.Accept(this) as Bool;
if (result != null && !result.Value)
{ return expr.Else.Accept(this); }
else
{ return expr.Then.Accept(this); }
}
public override Code Visit(Application expr)
{
var evaluatedFunction = expr.Function.Accept(this);
var appVisitor = new ApplicationVisitor(this, env, expr);
return evaluatedFunction.Accept(appVisitor);
}
}
public class ApplicationVisitor : Visitor
{
Visitor parentVisitor;
Application app;
Dictionary<string, Code> env;
public ApplicationVisitor(Visitor parentVisitor,
Dictionary<string, Code> env, Application app)
{
this.parentVisitor = parentVisitor;
this.env = env;
this.app = app;
}
public override Code Visit(Closure expr)
{
var envToExtend = expr.Env;
var len = expr.ParameterIdentifiers.Length;
var oldValues = new Code[len];
for (int i = 0; i < len; i++)
{
var name = expr.ParameterIdentifiers[i];
if (envToExtend.ContainsKey(name))
{ oldValues[i] = envToExtend[name]; }
envToExtend[name] = app.Args[i].Accept(parentVisitor);
} // Argumente mit env auswerten, Körper mit neuem env.
var result = expr.Body.Accept( // Dafür neuer Visitor:
new EvaluationVisitor(envToExtend));
for (int i = 0; i < len; i++)
{
var name = expr.ParameterIdentifiers[i];
if (oldValues[i] != null)
{ envToExtend[name] = oldValues[i]; }
}
return result;
}
public override Code Visit(BuiltInFunc expr)
{
var len = app.Args.Length;
var args = new Code[len];
for (int i = 0; i < len; i++)
{ args[i] = app.Args[i].Accept(parentVisitor); }
return expr.Apply(args);
}
protected override Code VisitDefault(Code expr)
{ throw new Exception("Cannot apply " + expr); }
}
public class Evaluator
{
public Code Evaluate(Code expr)
{ return expr.Accept(new EvaluationVisitor()); }
}
}
Listing 10: Test der Evaluator-Implementierungen in C#
using System;
using Microsoft.VisualStudio.TestTools.UnitTesting;
// Stellt eine Sammlung von Tests dar, die eine Evaluator-Implementierung überprüfen.
// Die Typparameter müssen den zu testenden Klassen entsprechen.
// Der Evaluator kapselt die Strategie, indem die Evaluate-Methode auf den Ausdruck angewendet und das Ergebnis geprüft wird.
// Die Klassen werden instanziiert und zu Test-Ausdrücken zusammengesetzt.
// Die statischen Methoden stellen die Tests dar. In Unterklassen müssen sie aufgerufen werden.
// Als Kommentar der einzelnen Tests steht ein exemplarischer Scheme-Ausdruck, der den Test darstellt.
// Der Test wird für gewöhnlich mit mehreren Prüfungen ausgeführt.
// (assert= actual expected) ist eine fiktive Funktion, die der Assert.AreEqual-Methode des Test-Frameworks enspricht.
public class DynamicTests<Code, Evaluator, LessThan, Equals, Plus, Number, Bool, Var, Binding, Conditional, Application, Lambda>
where Evaluator : new()
where LessThan : Code, new()
where Equals : Code, new()
where Plus : Code, new()
where Number : Code, new()
where Bool : Code, new()
where Var : Code, new()
where Binding : Code, new()
where Conditional : Code, new()
where Application : Code, new()
where Lambda : Code, new()
{
// (assert= (let ([x 20]) (+ x x 4))
// 44)
public static void LetPlus()
{
dynamic bind = new Binding();
dynamic variable = new Var();
dynamic plus = new Plus();
dynamic apply = new Application();
dynamic constant = new Number();
dynamic init = new Number();
variable.Name = "x";
bind.Identifier = "x";
bind.Value = init;
apply.Function = plus;
apply.Args = new Code[] { variable, variable, constant };
bind.Body = apply;
dynamic ev = new Evaluator();
for (int i = -100; i < 100; i++)
{
for (int k = -100; k < 100; k++)
{
constant.Value = i;
init.Value = k;
dynamic res = ev.Evaluate(bind);
Assert.AreEqual(2 * k + i, res.Value);
}
}
}
// (assert= ((lambda (a b) (if (< a b ) a b)) 1 2)
// 1)
public static void LambdaIfLess()
{
dynamic var1 = new Var();
dynamic var2 = new Var();
dynamic lt = new LessThan();
dynamic min = new Lambda();
dynamic cond = new Conditional();
dynamic apply1 = new Application();
dynamic apply2 = new Application();
dynamic num1 = new Number();
dynamic num2 = new Number();
var1.Name = "a";
var2.Name = "b";
min.ParameterIdentifiers = new[] { "a", "b", };
min.Body = cond;
cond.Condition = apply1;
apply1.Function = lt;
apply1.Args = new Code[] { var1, var2 };
cond.Then = var1;
cond.Else = var2;
apply2.Function = min;
num1.Value = 1;
num2.Value = 2;
apply2.Args = new Code[] { num1, num2 };
dynamic eval = new Evaluator();
for (int i = -100; i < 100; i++)
{
for (int k = -100; k < 100; k++)
{
num1.Value = i;
num2.Value = k;
dynamic result = eval.Evaluate(apply2);
Assert.AreEqual(Math.Min(i, k), result.Value);
}
}
}
// (assert=
// ((lambda (cont x) (if (= x 0) 1 (+ x (cont cont (+ x -1)))))
// (lambda (cont x) (if (= x 0) 1 (+ x (cont cont (+ x -1)))))
// 4)
// 11) // Wie Fakultät nur mit + statt *: 1, 2, 4, 7, 11, 16, 22, 29, ...
public void ContinuationRecursion()
{
dynamic fun = new Lambda();
dynamic cont = new Var();
dynamic x = new Var();
dynamic eq = new Equals();
dynamic input = new Number();
dynamic cond = new Conditional();
dynamic recurse = new Application();
dynamic plus = new Plus();
dynamic applyPlus = new Application();
dynamic applyEq = new Application();
dynamic subtractOne = new Application();
dynamic negOne = new Number();
dynamic zero = new Number();
dynamic one = new Number();
dynamic test = new Application();
zero.Value = 0;
one.Value = 1;
negOne.Value = -1;
x.Name = "x";
cont.Name = "cont";
fun.ParameterIdentifiers = new[] { "cont", "x" };
fun.Body = cond;
applyEq.Function = eq;
applyEq.Args = new Code[] { x, zero };
cond.Condition = applyEq;
cond.Then = one;
cond.Else = applyPlus;
applyPlus.Function = plus;
applyPlus.Args = new Code[] { x, recurse };
recurse.Function = cont;
recurse.Args = new Code[] { cont, subtractOne };
subtractOne.Function = plus;
subtractOne.Args = new Code[] { x, negOne };
test.Function = fun;
test.Args = new Code[] { fun, input };
dynamic eval = new Evaluator();
for (int i = 0; i < 100; i++)
{
input.Value = i;
dynamic result = eval.Evaluate(test);
var sum = 1;
for (int counter = 1; counter <= i; counter++)
{ sum += counter; }
Assert.AreEqual(sum, result.Value);
}
}
// cons = (lambda (hd tl) (lambda (takeHead)(if takeHead hd tl)))
// head = (lambda (consCell) (consCell true))
// tail = (lambda (consCell) (consCell false))
// isEmpty = (lambda (consCell) (if consCell #f #t))
// oneTwo = (cons 1 (cons 2 #f))
// (assert= (head oneTwo) 1)
// (assert= (head (tail oneTwo)) 2)
// (assert= (tail (tail oneTwo)) #f)
// (assert= (isEmpty oneTwo) #f)
// (assert= (isEmpty (tail oneTwo)) #f)
// (assert= (isEmpty (tail (tail oneTwo))) #t)
public void ListClosure()
{
dynamic cons = new Lambda();
dynamic consSelect = new Lambda();
dynamic consSelectIf = new Conditional();
dynamic takeHead = new Var();
dynamic headVar = new Var();
dynamic tailVar = new Var();
takeHead.Name = "takeHead";
headVar.Name = "head";
tailVar.Name = "tail";
cons.ParameterIdentifiers = new[] { "head", "tail" };
cons.Body = consSelect;
consSelect.ParameterIdentifiers = new[] { "takeHead" };
consSelect.Body = consSelectIf;
consSelectIf.Condition = takeHead;
consSelectIf.Then = headVar;
consSelectIf.Else = tailVar;
dynamic head = new Lambda();
dynamic headApp = new Application();
dynamic trueBool = new Bool();
dynamic consCellVar = new Var();
consCellVar.Name = "consCell";
trueBool.Value = true;
head.ParameterIdentifiers = new[] { "consCell" };
head.Body = headApp;
headApp.Function = consCellVar;
headApp.Args = new Code[] { trueBool };
dynamic tail = new Lambda();
dynamic tailApp = new Application();
dynamic falseBool = new Bool();
falseBool.Value = false;
tail.ParameterIdentifiers = new[] { "consCell" };
tail.Body = tailApp;
tailApp.Function = consCellVar;
tailApp.Args = new Code[] { falseBool };
dynamic isEmpty = new Lambda();
dynamic isEmptyIf = new Conditional();
dynamic xs = new Var();
xs.Name = "xs";
isEmpty.ParameterIdentifiers = new[] { "xs" };
isEmpty.Body = isEmptyIf;
isEmptyIf.Condition = xs;
isEmptyIf.Then = falseBool;
isEmptyIf.Else = trueBool;
dynamic one = new Number();
one.Value = 1;
dynamic two = new Number();
two.Value = 2;
dynamic twoList = new Application();
twoList.Function = cons;
twoList.Args = new Code[] { two, falseBool };
dynamic oneTwo = new Application();
oneTwo.Function = cons;
oneTwo.Args = new Code[] { one, twoList };
dynamic ev = new Evaluator();
dynamic headTest = new Application();
headTest.Function = head;
headTest.Args = new Code[] { oneTwo };
dynamic num = ev.Evaluate(headTest);
Assert.AreEqual(1, num.Value);
dynamic tailOfOneTwo = new Application();
tailOfOneTwo.Function = tail;
tailOfOneTwo.Args = new Code[] { oneTwo };
dynamic headOfTailTest = new Application();
headOfTailTest.Function = head;
headOfTailTest.Args = new Code[] { tailOfOneTwo };
num = ev.Evaluate(headOfTailTest);
Assert.AreEqual(2, num.Value);
dynamic tailOfTailTest = new Application();
tailOfTailTest.Function = tail;
tailOfTailTest.Args = new Code[] { tailOfOneTwo };
dynamic empty = ev.Evaluate(tailOfTailTest);
Assert.AreEqual(false, empty.Value);
dynamic isEmptyTest = new Application();
isEmptyTest.Function = isEmpty;
isEmptyTest.Args = new Code[] { oneTwo };
empty = ev.Evaluate(isEmptyTest);
Assert.AreEqual(false, empty.Value);
isEmptyTest.Args = new Code[] { tailOfOneTwo };
empty = ev.Evaluate(isEmptyTest);
Assert.AreEqual(false, empty.Value);
isEmptyTest.Args = new Code[] { tailOfTailTest };
empty = ev.Evaluate(isEmptyTest);
Assert.AreEqual(true, empty.Value);
}
}
// Es folgen die Tests der einzelnen Implementierungen. Sie befinden sich in einem Namespace,
// damit dort die Klassen mit using importiert werden können.
// Dies sind die Typparameter der Test-Sammlung.
// Die Namen der Test-Methoden enthalten den Namen des Implementierungsansatzes,
// um schnell zu sehen, welcher Implementierungsaspekt welches Ansatzes fehlerhaft war.
namespace TypetestsTest
{
using Typtests;
[TestClass]
public class Test : DynamicTests<Code, Evaluator, LessThan, Equals, Plus, Number, Bool, Var, Binding, Conditional, Application, Lambda>
{
[TestMethod]
public void TyptestsLambdaIfLess() { LambdaIfLess(); }
[TestMethod]
public void TyptestsLetPlus() { LetPlus(); }
[TestMethod]
public void TyptestsContinuationRecursion() { ContinuationRecursion(); }
[TestMethod]
public void TyptestsClosure() { ListClosure(); }
}
}
namespace TypeCodesTest
{
using TypeCodes;
[TestClass]
public class Test : DynamicTests<Code, Evaluator, LessThan, Equals, Plus, Number, Bool, Var, Binding, Conditional, Application, Lambda>
{
[TestMethod]
public void TypeCodesLambdaIfLess() { LambdaIfLess(); }
[TestMethod]
public void TypeCodesLetPlus() { LetPlus(); }
[TestMethod]
public void TypeCodesContinuationRecursion() { ContinuationRecursion(); }
[TestMethod]
public void TypeCodesClosure() { ListClosure(); }
}
}
namespace PolymorphieTest
{
using Polymorphie;
[TestClass]
public class Test : DynamicTests<Code, Evaluator, LessThan, Equals, Plus, Number, Bool, Var, Binding, Conditional, Application, Lambda>
{
[TestMethod]
public void PolymorphieLambdaIfLess() { LambdaIfLess(); }
[TestMethod]
public void PolymorphieLetPlus() { LetPlus(); }
[TestMethod]
public void PolymorphieContinuationRecursion() { ContinuationRecursion(); }
[TestMethod]
public void PolymorphieClosure() { ListClosure(); }
}
}
namespace VisitorsTest
{
using Visitors;
[TestClass]
public class Test : DynamicTests<Code, Evaluator, LessThan, Equals, Plus, Number, Bool, Var, Binding, Conditional, Application, Lambda>
{
[TestMethod]
public void VisitorsLambdaIfLess() { LambdaIfLess(); }
[TestMethod]
public void VisitorsLetPlus() { LetPlus(); }
[TestMethod]
public void VisitorsContinuationRecursion() { ContinuationRecursion(); }
[TestMethod]
public void VisitorsClosure() { ListClosure(); }
}
}
 zeigt sich der große Unterschied: Seq.reduce (*) {1..n} als deklarativer F#-Ausdruck und in C# als imperative Berechnungsvorschrift:
zeigt sich der große Unterschied: Seq.reduce (*) {1..n} als deklarativer F#-Ausdruck und in C# als imperative Berechnungsvorschrift: ist beispielsweise in Prolog als richtungsabhängiges Prädikat zu schreiben: square(N, NmalN) :- NmalN is N * N..
ist beispielsweise in Prolog als richtungsabhängiges Prädikat zu schreiben: square(N, NmalN) :- NmalN is N * N..
 dargestellt wird. Programmierer sollten auch Zugriff auf dieses Konstrukt haben und könnten sich eine entsprechende Funktion definieren. Für das (n-stellige) Produkt gibt es
dargestellt wird. Programmierer sollten auch Zugriff auf dieses Konstrukt haben und könnten sich eine entsprechende Funktion definieren. Für das (n-stellige) Produkt gibt es 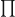 , welches sich auch definieren ließe. Die Integration von erweiterten Unicode-Zeichen in Programmiersprachen ist noch nicht gelungen, was an Schwierigkeiten bei der Eingabe mit der Tastatur und unflexiblen Parsern liegt.Eine Betrachtung des Themas Unicode in Programmiersprachen findet in [FunktProg, S. 4-5] statt. Daher werden sprechende Namen statt mathematischer Symbole verwendet:
, welches sich auch definieren ließe. Die Integration von erweiterten Unicode-Zeichen in Programmiersprachen ist noch nicht gelungen, was an Schwierigkeiten bei der Eingabe mit der Tastatur und unflexiblen Parsern liegt.Eine Betrachtung des Themas Unicode in Programmiersprachen findet in [FunktProg, S. 4-5] statt. Daher werden sprechende Namen statt mathematischer Symbole verwendet: ) ist leicht verständlich: int -> int. Im Fall von partieller Applikation sehen Funktionstypen etwas interessanter aus. Arithmetische Operationen (etwa +, -, *, /) und Vergleiche (wie >, <=) erwarten zwei Argumente, um ausgeführt zu werden. Die Applikation des Operators auf das erste Argument liefert eine Funktion, die nur noch das zweite Argument erwartet. Das wird im Fall der Addition für Ganzzahlen so dargestellt: int -> (int -> int). Der Eingabetyp ist int, d.h. der erste Eingabewert ist eine ganze Zahl und der Ausgabetyp ist eine Funktion vom Typ int -> int. Dies stellt den Typen der Funktion dar, die das zweite Argument erwartet. Die Klammerung von Funktionstypen ist rechtsassoziativ, deshalb wird statt int -> (int -> int) gerne int -> int -> int geschrieben.
) ist leicht verständlich: int -> int. Im Fall von partieller Applikation sehen Funktionstypen etwas interessanter aus. Arithmetische Operationen (etwa +, -, *, /) und Vergleiche (wie >, <=) erwarten zwei Argumente, um ausgeführt zu werden. Die Applikation des Operators auf das erste Argument liefert eine Funktion, die nur noch das zweite Argument erwartet. Das wird im Fall der Addition für Ganzzahlen so dargestellt: int -> (int -> int). Der Eingabetyp ist int, d.h. der erste Eingabewert ist eine ganze Zahl und der Ausgabetyp ist eine Funktion vom Typ int -> int. Dies stellt den Typen der Funktion dar, die das zweite Argument erwartet. Die Klammerung von Funktionstypen ist rechtsassoziativ, deshalb wird statt int -> (int -> int) gerne int -> int -> int geschrieben.
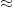 match Ausdruck with Muster -> Körper
match Ausdruck with Muster -> Körper sortiert. Der Code ist in F# geschrieben und ist ein gutes Beispiel für ein effizienten imperativen Algorithmus. Zuweisungen in F# werden mit dem Pseudocode-Pfeil <- notiert; Zuweisungen von veränderbaren Variablen (die mit let mutable deklariert wurden) und von Array-Elementen sind erlaubt.
sortiert. Der Code ist in F# geschrieben und ist ein gutes Beispiel für ein effizienten imperativen Algorithmus. Zuweisungen in F# werden mit dem Pseudocode-Pfeil <- notiert; Zuweisungen von veränderbaren Variablen (die mit let mutable deklariert wurden) und von Array-Elementen sind erlaubt.